
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- ci/cd
- AWS
- kubernetes
- ASG
- docker
- Typesript
- TypeScript
- ELB
- REPLICATION
- Jenkins
- 코드프레소
- Redis
- codepresso
- Elastic Load Balancing
- 아키텍처
- springboot
- k8s
- Auto Scaling Group
- NoSQL
- Today
- Total
Study Note
NoSQL 데이터 모델링 본문
NoSQL/RDBMS의 데이터 모델링 차이
쿼리결과 지향 모델링
NoSQL은 복잡한 쿼리를 할 수 없기 때문에 필요한 쿼리를 정의하고 데이터 저장 모델인 테이블을 디자인 한다.
- RDBMS : 도메인 모델 -> 테이블 -> 쿼리
- NoSQL : 도메인 모델 -> 쿼리 -> 테이블
역정규화
- RDBMS : 모델링은 데이터 일관성과 도메인 모델의 일치성을 위해 데이터 모델을 정규화한다.
- NoSQL : 쿼리의 효율성을 위해 데이터를 의도적으로 중복해서 저장하는 것과 같이 데이터 모델을 비정규화 한다.
NoSQL 데이터 모델링 패턴
NoSQL은 RDBMS의 쿼리 기능들 (ORDER BY, GROUP BY, JOIN, INDEX)을 지원하지 않기 때문에 데이터 모델링을 통해 쿼리 기능들을 구현해야 한다.
기본적인 데이터 모델링 패턴
역정규화 (Denomalization)
RDBMS에서 User/City 테이블은 다음과 같은 관계를 가지고 있다. RDBMS에서는 이런 구조에서 JOIN을 통해서 1번의 쿼리로 name, age, sex, zip code를 검색할 수 있다.

NoSQL은 JOIN을 할수 없기 때문에 2번의 쿼리를 실행해야 하며 이는 I/O 횟수가 증가 함을 의미한다.
NoSQL에서 JOIN된 테이블을 다음과 같이 추가하면 1번의 쿼리로 같은 결과를 얻을수 있다.

역정규화를 이용한 중복 허용의 장점
-
성능향상
-
쿼리의 복잡도가 낮아짐
역정규화를 통해 중복 허용의 단점
- 스토리지 용량 증가
-
데이터 일관성 문제 발생 가능
데이터 일관성 문제의 예시로 Age가 변경되면 User Table과 UserZipCode 모두 수정해야 하지만 수정중에 UserZipCode에서 에러가 발생하여 수정되지 않으면 User Table과 UserZipCode의 데이터가 불일치 한다.
집계 (Aggregation)
개인용 스토리지 서비스에서 파일을 저장할때 파일 종류에 따라 추가적인 메타 정보를 저장할때 RDBMS에서 다음과 같은 구조가 생긴다.
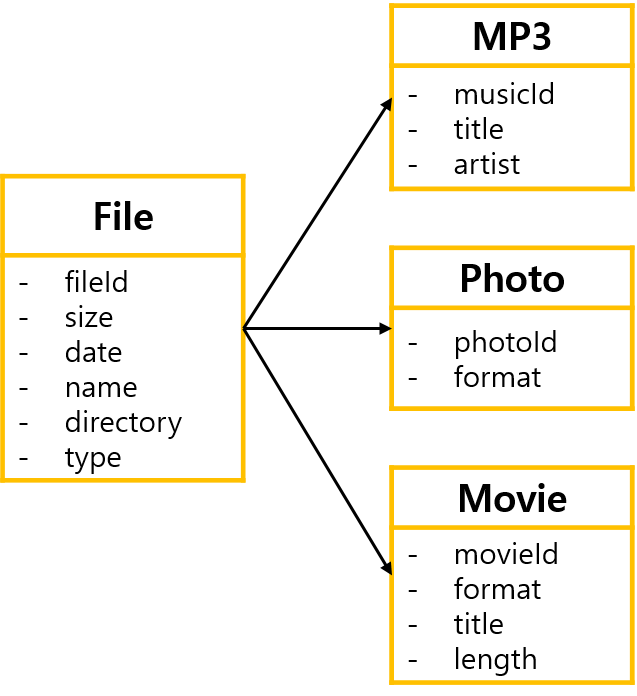
NoSQL은 Schemeless나 Sort Scheme라고 불리는 특성 때문에 데이터 구조가 각각 다를 수 있다.
이렇게 하면 1:N인 복잡한 구조를 하나의 테이블로 바꿔서 쿼리 수를 줄여 성능을 향상시킬수 있다.

어플리케이션 조인 (Application Side Join)
JOIN은 대부분의 NoSQL에서 불가능 하다. 역정규화, 집계를 이용할 수 없는 상황에서는 NoSQL을 사용하는 사용자가 처리해줘야 한다. 간단히 RDBMS에서 Table1이 Table2에 대한 FK를 가지고 있어 Table1을 읽어온 후에 FK를 가지고 Table2를 읽는 방법이다.
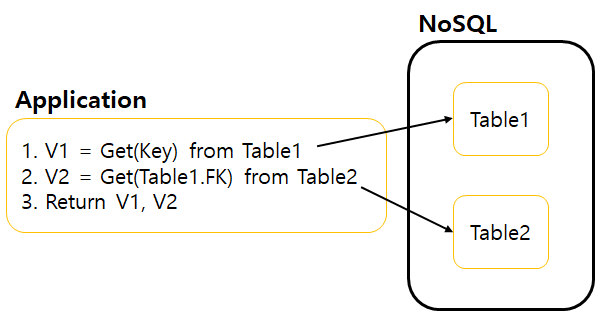
확장된 데이터 모델링 패턴
Atomic Aggregation
NoSQL은 테이블 단위로 원자성을 보장하기 때문에 다수의 테이블에 동시에 업데이트 할 때 문제가 생길수 있다. 이런 문제는 테이블을 합침으로써 해결할 수 있다.
기본적인 데이터 모델링 패턴의 집계(Aggregation)와 구현 패턴은 같지만 집계는 JOIN을 없에기 위해서 사용하지만 Atomic Aggregation은 트랜잭션을 보장하여 데이터 불일치를 없에기 위해 사용한다.
Index Table
NoSQL은 index가 없기 때문에 Key을 제외한 필드에서 검색하면 Full Scan을 하거나 검색이 불가능하다. index Table을 만들어서 사용하면 이런 문제를 해결 할 수 있다.

만약 NoSQL의 Secondary Index가 있는 제품을 사용해서 Secondary Index를 사용할 경우 index Table을 사용한 방법과 성능을 잘 비교해서 사용해야 한다.
Composite Key
Key를 정의할 때 콜론(:)을 이용한 복합 Key를 사용하는 방법이다. RDBMS의 복합 Key와 같은 개념이지만 RDBMS는 여러 컬럼을 묶어 복합 Key를 만들지만, NoSQL은 한 컬럼에 구분자를 사용하여 여러 키를 묶는 형태이다.

NoSQL은 여러 서버로 구성되어 있고 Key를 기준으로 각 서버에 나눠서 저장한다. NoSQL의 이런 특성 때문에 Composite Key를 사용할 경우 특정 서버로 데이터가 몰리는 현상이 발생 할수 있다. 이런 이유로 서버 전체로 부하가 분산될 수 있는 Key를 사용하는게 좋다.
Inverted Search Index
Key를 Value로 Value를 Key로 바꾼 패턴을 Inverted Search Index라고 한다.
검색 엔진에서 많이 사용하는 방법으로 다음 그림과 같이 검색 엔진에선 특정 단어를 Key로 URL을 Value로 맴핑해서 저장 한다.

Enumerable Keys
RDBMS의 Sequence와 같은 기능을 NoSQL의 제품에 따라 사용 가능하다. RDBMS의 Auto Increment 처럼 Key를 자동으로 올려주는 기능이다. 특정 Key의 앞, 뒤로 어떤 Key가 올지 알수 있는 것처럼 데이터에 트래버스 기능을 제공한다.
이 글은 저: 조대협님의 "대용량 아키텍처와 성능 튜닝"을 읽고 공부한 내용입니다.
이 글은 코드프레소 DevOps Roasting 코스를 수강하면서 작성한 글입니다.
'아키텍처 > 대용량 아키텍처' 카테고리의 다른 글
| NoSQL 데이터 모델링 절차 (0) | 2020.02.07 |
|---|---|
| NoSQL이란? (0) | 2020.02.07 |

